[데이터분석/통계기초] 데이터 체계화 및 시각화 - 도수분포, 상대도수, 누적도수
바야흐로(?) 빅데이터의 시대, 오늘부터는 데이터를 분석하고 유의미한 인사이트를 얻어내기 위해 반드시 필요한 action, 통계분석 방법론을 차근차근 다뤄볼 예정이다.
그동안 필요한 범위 내에서 엑셀기반의 데이터 분석들을 드물게 해 왔지만, 도출한 데이터/결과값을 효과적으로 시각화하기 위해서 어떻게 접근해야 할지 막막했던 그 모든 순간들을 기억하며, 학창 시절 기피했던 '통계'와 조금씩 친해져보려고 한다. 이 글을 읽는 분들이 거의 처음 통계를 접하거나 아주 오랜만에 통계를 찾아보는 분들이라면, 저와 같이 차근차근 공부하는 마음으로 통계시리즈를 읽어 주시길 바라며 😊
1. 도수분포 (Frequency distributions)
데이터의 분포를 확인하자, 도수분포표와 히스토그램
도수 분포표(Frequency Table)란 데이터의 분포를 몇 개의 구간으로 분류하고, 각 구간에 속하는 데이터가 몇 개인지 분포를 정리한 표를 말한다. 구간을 나누어 분포를 확인하면 데이터의 전체적인 모양을 간편히 확인해 인사이트를 얻을 수 있기 때문에 유용하게 쓰인다.
예) 학생들의 중간고사 성적을 1~10점부터 90~100점까지 구간별로 나누고, 각 구간별 인원수를 세보면 중간고사 난이도를 쉽게 파악할 수 있을 것이다. (하위 성적에 많은 수의 학생이 있다면 시험 난이도가 높았거나 학생들의 학습수준이 낮을 것으로, 상위 성적에 많은 수의 학생이 있다면 시험이 평이했거나 학생들의 학습수준이 높다고 유추할 수 있다.)
도수분포표 작성을 위해 구간을 나눌 때는 다음 방법으로 접근한다.
① 전체 데이터 중 최댓값과, 최소값을 찾는다.
② 몇개 구간으로 나눌지 결정한다.
③ 구간폭을 정한다 (최댓값-최소값/정한 구간수 * 정수/짝수/5의 배수를 사용하는 것이 편리!)
→ 구간수를 편리하게 산정하기 위한 Sturge's formula : c(구간 개수) = 1+3.3 log n(전체 데이터 개수)
히스토그램은 도수분포표의 내용이 한눈에 들어오도록 시각화한 차트로, x축은 구간을 y축은 빈도를 나타낸다.
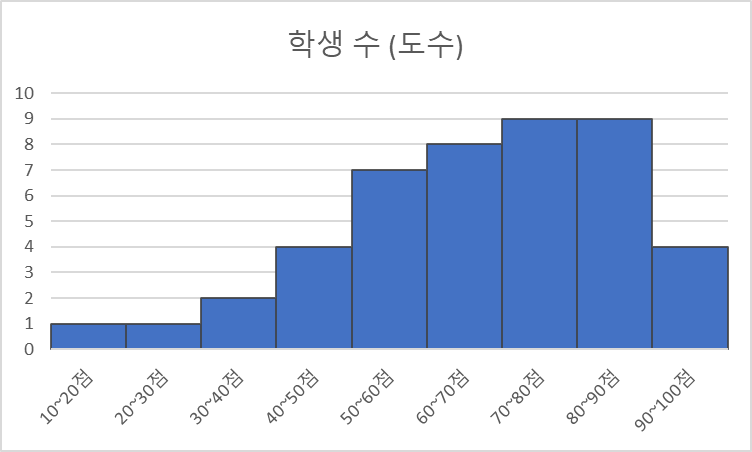
[도수분포표 예]
| 성적 구간 (계급) | 학생 수 (도수) |
| 10~20점 | 1 |
| 20~30점 | 1 |
| 30~40점 | 2 |
| 40~50점 | 4 |
| 50~60점 | 7 |
| 60~70점 | 8 |
| 70~80점 | 9 |
| 80~90점 | 9 |
| 90~100점 | 4 |
| 합계 | 45 |
[히스토그램 예]
2. 상대도수와 상대도수의 분포 (Relative frequency and percentage distributions)
각 분포의 구간별 비율을 나타내는 상대도수와 상대도수 분포표/도수분포다각형
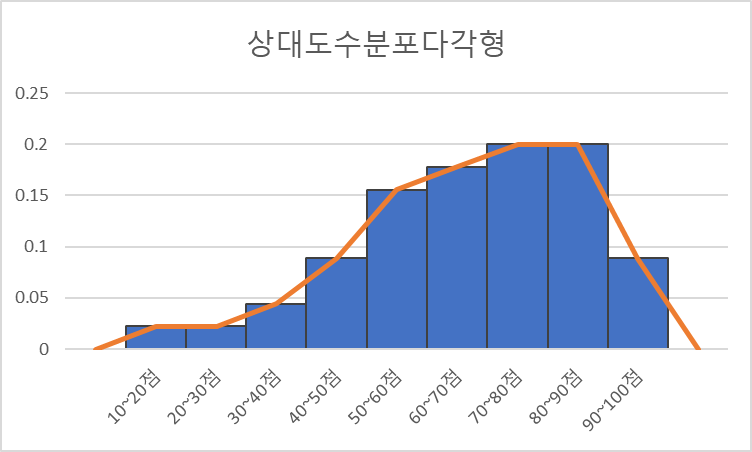
상대 도수란 전체 도수에 대한 각 계급(구간) 내 도수의 비율을 말한다. 각 구간별 비교를 쉽게 하기 위해 상소수(백분율)로 나타내며, 모든 구간 상대도수의 합은 항상 1이다. 상대도수를 그래프로 나타날 때는 가로축에는 계급(구간), 세로축에는 상대도수를 넣어 히스토그램이나 도수분포 다각형으로 나타낸다.
어떤 계급(구간)의 상대도수 = 그 계급의 도수 / 전체도수
[상대도수 분포표 예]
| 성적 구간 (계급) | 상대도수 |
| 10~20점 | 0.02 (2%) |
| 20~30점 | 0.02 (2%) |
| 30~40점 | 0.04 (4%) |
| 40~50점 | 0.09 (9%) |
| 50~60점 | 0.16 (16%) |
| 60~70점 | 0.18 (18%) |
| 70~80점 | 0.20 (20%) |
| 80~90점 | 0.20 (20%) |
| 90~100점 | 0.09 (9%) |
| 합계 | 1.00 (100%) |
[상대도수를 나타낸 도수분포다각형 예]
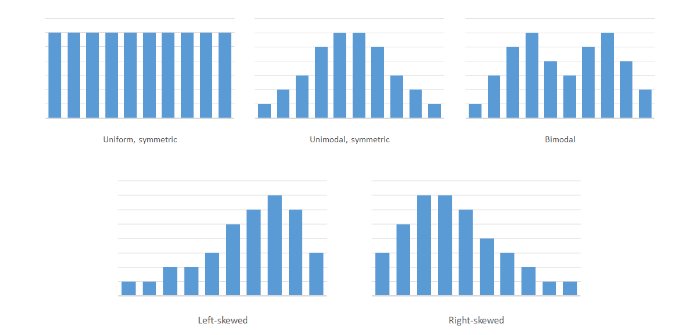
히스토그램으로 보는 데이터 분포의 종류
히스토그램을 살펴보면 수집한 데이터가 어떤 성격을 띄는지, 데이터의 의미를 금방(?) 알 수 있다.
- symmetric: 정규분포 (중앙에 데이터 분포가 모여 평균값을 띄는 형태)
- bimodal: 성격이 다른 두 집단이 모여 만든 분포 (정규분포 x 2)
- left-skewed / right-skewed: 평균값이 한쪽으로 치우친 데이터 (공부 잘하는 학생들이 많으면 시험 성적은 left skewed 확률이 높겠죠?)
- uniform: 가장 고루 고루 분포한 데이터
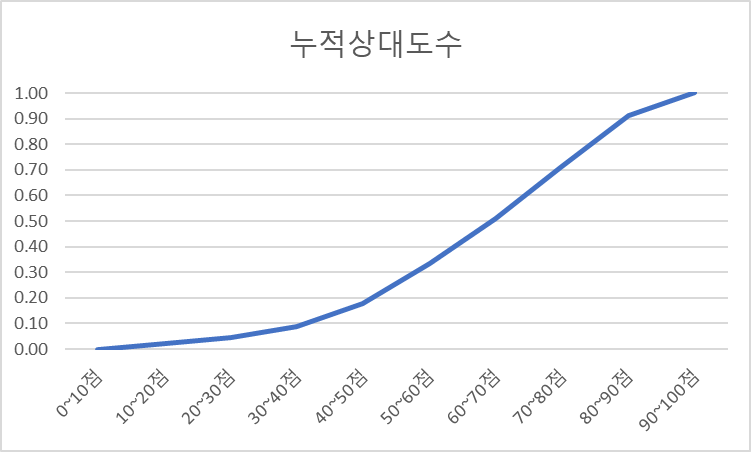
3. 누적 상대도수의 분포
분포의 형태를 볼 수 있는 누적 상대도수는 누적 도수의 합을 데이터의 총수로 나눈 것을 말한다. 데이터 수가 많은 집단의 분포 형태를 검토할 때 사용한다.
*아래 구간에 누적 상대도수가 높으면 분포가 아래쪽에 몰린 것, 위 구간이 높으면 분포가 위에 몰린 것
*누적상대도수가 0.5일 때를 중앙값, 0.25를 제1사분위, 0.75를 제3사분위라 한다. (이 부분은 나중에 box plot을 보며 다시 다룰 예정!)
누적상대도수 = 누적 도수의 합 / 전체도수
[누적상대도수 분포표 예]
| 성적 구간 (계급) | 누적상대도수 |
| 10~20점 | 0.02 |
| 20~30점 | 0.04 |
| 30~40점 | 0.09 |
| 40~50점 | 0.18 |
| 50~60점 | 0.33 |
| 60~70점 | 0.51 |
| 70~80점 | 0.71 |
| 80~90점 | 0.91 |
| 90~100점 | 1.00 |
| 합계 | 1.00 |
[누적상대도수 분포 그래프 예]